





The Radically Simple Guide to: Building Next Gen dApps with Cartesi
Everything you need to know to start building on Cartesi
Written By Marketing Unit
In Endgame, Vitalik Buterin contemplated a world in which Ethereum becomes a specialized data availability and security layer. Since that time, both Arbitrum and Optimism have seen impressive adoption as specialized execution and settlement layers. Cartesi, in turn, has focused on providing app-specific modular execution environments that can run atop these various other layers of the stack.
This shift towards a modular framework can help mitigate the effects of network congestion, which has proven itself a very real obstacle to meaningful adoption. Periods of heavy usage during DeFi Summer (2020) and NFT Summer (2021) exposed an uncomfortable truth about the most widely used L1: Ethereum becomes little more than a rich person’s playground when participants are pushed into bidding wars for the finite computational attention of nodes that validate the network’s state.
Fortunately, innovations in transactional and computational scalability have enabled synergistic designs that can reduce demand for Ethereum’s computational resources. The key: reducing the need for global consensus on every single action in the network.
Embracing a modular stack now allows us to explore the frontier of modular consensus, empowering applications and users to define their own optimal levels of consensus locality, while maintaining the strong security guarantees of a highly decentralized global base layer.
In a network where block size is effectively capped (such as through Ethereum’s gas limits), we are necessarily capping the supply of available computing power. As a result, block size effectively defines the saturation point of the network’s computational attention. A consensus node, no matter how big or mighty, only ever dedicates one block’s worth of computational attention (space/time) to the universe of user demands in any given moment.
As the number of transactions grows and dApp functionality becomes more expressive, network users are forced to compete for the increasingly scarce computational attention of nodes verifying the network’s state. In such a universe, applications and users who can’t afford to engage in a bidding war for this finite supply of computing power are necessarily excluded from participating.
So how can we create a more inclusive system?
One oft-debated solution is to increase the computing power of the network by increasing block size (let’s bring that big node energy!). While it may seem to be the simplest path, this strategy comes at a heavy cost to decentralization. Any material increase in block size would make consensus node software more resource-intensive, and therefore more cost-prohibitive for many participants to run. In light of this increased centralization risk, Vitalik Buterin has described this strategy of increasing network supply as “fundamentally a dead end.”[1]
If we value decentralization (which we do!), we must instead design systems that efficiently govern demand for computational attention across the blockchain ecosystem as a whole.
Protocols that wish to see blockchain technology become truly accessible and expressive must empower users to define what actions should demand the computational attention of the entire network (i.e. global consensus), and what actions can be delegated to specialized actors whose computational attention need not be similarly constrained (i.e. local consensus).
Let’s explore the spectrum of consensus locality using some existing arrangements in the Ethereum ecosystem, and briefly discuss their benefits and tradeoffs. To simplify the conversation, let’s assume that each universe capable of attaining consensus has precisely one CPU of computational attention to spare. Every time an application in a given universe asks the CPU to verify an action, it demands an allocation of the total supply of computational attention available in that universe.
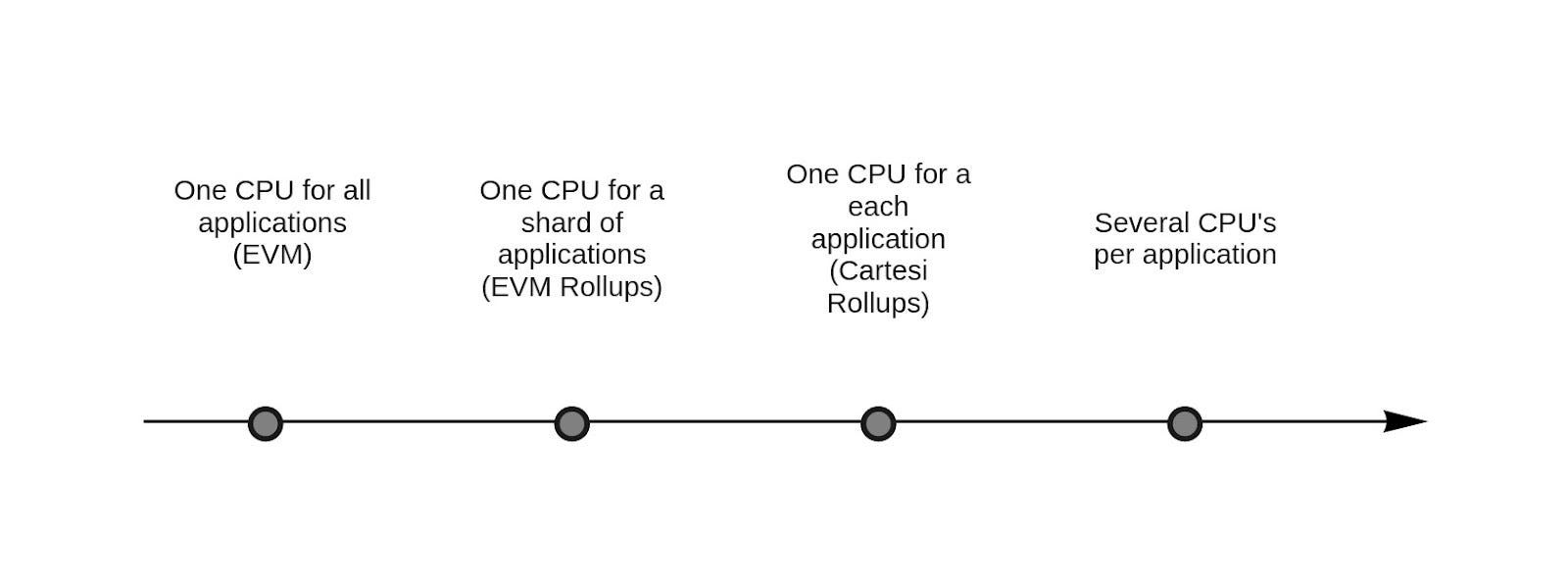
Ethereum: all applications run together in the same universe
In this L1 universe, to interact trustlessly with a fruit stand down the street, one must verify all interactions happening inside a casino on another planet, and a rocket rink in another galaxy.
The main benefit of running all applications in the same universe (verified by the same CPU) is frictionless composability. Different applications operating in the same universe can communicate, integrate, and exchange assets seamlessly. But there’s a relevant price to be paid for this convenience. The fruit stand, casino, rocket rink, and all other applications in the universe compete cannibalistically for a scarce share of the CPU’s computational attention.
As a result of this infighting, innovation is hindered. Applications forgo optimizing for their highest purpose in favor of reducing their interactions with the CPU. Small players can’t afford to brawl for a disputed share of the network’s computing power. The universe becomes gentrified.
Ultimately, only applications that can pay the price (primarily dApps with a financial focus) survive this harsh environment.
Arbitrum One or Optimism: some applications run together in a parallel universe to escape overcrowding in the L1 universe
Unable to compete with the growing contingent of DeFi Death Stars in the L1, the fruit stand and casino move to a smaller, parallel universe with its own CPU. In this new environment, the person buying peaches at the fruit stand still has to verify all of the casino’s interactions. But because this parallel universe has far fewer inhabitants, competition for the CPU’s computational attention is not as fierce. What’s more, participants in this new network are no longer placing as frequent demands on the L1’s computational attention.
Innovation now has room to breathe in both universes.
There’s still excellent composability for applications running together inside this parallel universe (the fruit stand can seamlessly offer mango vouchers to the casino’s most loyal degens). On the downside, we’ve now added some friction when it comes to communicating with other universes (the L1). But for many applications and users, that’s a worthwhile tradeoff in exchange for less competition over the CPU’s attention.
Critically, the complete state of this parallel universe is still shared every so often with the L1 (through a decentralized hyperspace portal that can effectuate inter-universal data transfers, obvi).
For the fruit stand and its customers, “every so often” is often enough when it comes to keeping the global state apprised of multiverse kiwi consumption!
Cartesi Rollups: each application runs in its own universe.
The fruit market has gone absolutely bananas. Demand for potassium is through the roof. The fruit stand ditches the casino and moves to its own private universe. Now, the person buying strawberries and pears (and, of course, bananas!) doesn’t even know the casino exists.
With a dedicated CPU all to itself, the fruit stand no longer has to fight for computational attention at all. This gain in computing power provides the fruit stand with orders-of-magnitude improvement in cost efficiency, computational scalability, predictability, and user experience. It’s a gain so powerful that our decentralized fruit stand now has a proper OS to run on — file system included!
Our fruit stand still periodically keeps the global state apprised of its activities. But now, even fewer demands are being placed on the computational resources of parallel universes, unlocking even more innovative potential for the multiverse as a whole.
To be sure, the fruit stand faces yet another layer of bureaucracy when communicating with other applications and universes. But the gains associated with an increase in computing power now allow the fruit stand to pursue its own highest calling.
CPU-Specific Chains (Secondary Rollups): each application can summon multiple universes
The fruit stand has met Morpheus. It’s been freed from the Matrix.
Each fruit now commands its own universe. Mango munchers validate only the mangoes they’re munching. They don’t compete for attention with apple apologists.
They’ve never even heard of a casino before.
Here, dApps start to mimic traditional applications with respect to both cost efficiency and the immense computational scalability that comes from the ability to parallelize.
A synergy of specialized agents, each with the ability to scale either data or computation by orders of magnitude in parallel, is required if we are to see decentralized blockchain technology become truly accessible and expressive.
To that end, we must consciously design systems that reduce globalized demand for computing power, empowering applications and their users to choose an optimal level of consensus locality based on their own decentralization, security, computation, composability, and financial considerations.
Special thanks to Erick de Moura and Augusto Texeira for their valuable reviews and help writing this piece.
[1] Buterin, V. [@VitalikButerin]. (August 20, 2020). BSV’s strategy (pursuing maximally big block sizes) increases capacity at the cost of making the chain more and more difficult . . . [Tweet]. Twitter.
Join our newsletter to stay up to date on features and releases
Everything you need to know to start building on Cartesi
Written By Marketing Unit
Your go-to guide to understanding the power of Linux onchain.
Written By Marketing Unit
Exciting news! The Cartesi
Written By CARTESI FOUNDATION








© 2024 The Cartesi Foundation. All rights reserved.




